 en
en br
brDemo Firebird Encryption
How to encrypt the database with IBSurgeon's encryption plugin for Firebird
In the short guide below, we will demonstrate the key features of the encryption: how to encrypt your Firebird database on the server, how to implement an encrypted client connection, and perform backup/restore of the encrypted database.The demo of Framework is fully functional, with the only exception - it is limited until January 30, 2024
Contents:
- Prerequisites
- Step 1: Initial encryption of database
- Step 2: Connect to the encrypted database with a client sample application
- Step 3: Connect to the encrypted database with developer tools
- Step 4: Backup and restore of the encrypted database
Prerequisites
To implement Firebird encryption, you need the following:- Download CryptTest.zip archive with the demo version of Encryption Plugin and demo client application with sources.
- Firebird 3.0.3 or higher – to test the demo plugin it is necessary to use official release 3.0 64bit or 32bit (versions 3.0.3 - 3.0.12, 4.0.0 - 4.0.4 are supported). If you are using HQbird Enterprise 2022+, no need to download plugin files, they are already there. Older versions are not supported by the demo version of the plugin.
- Create SYSDBA user, if it is not created (stop Firebird service, run isql -user sysdba employee.fdb, execute command CREATE USER SYSDBA PASSWORD 'masterkey', start Firebird service)
- In the steps below we suppose that all actions will be made with 64-bit version of the Firebird 3.0.3+, in case of 32-bit version simply use the files from WinSrv32bit_ServerPart folder, or the appropriate Linux folder from CryptTest.zip archive.
Step 1: Initial encryption of the database
At this point, we suppose that you have some database to be encrypted. Put unencrypted database to some path, for example, into c:\temp\employee30\employee.fdb1. Create the following alias in databases.conf
crypt = C:\Temp\EMPLOYEE30\EMPLOYEE30.FDB
{
KeyHolderPlugin = KeyHolder
}
Also, you can declare KeyHolder plugin for all databases at the server, for this add the following parameter to firebird.conf:
KeyHolderPlugin = KeyHolderor, simply copy firebird.conf at step 2 (see below)
2. Put the following files to server/plugins from the folder \Windows_64bit\WindowsServerPart_64bit\plugins (from CryptTest.zip demo archive)
- DbCrypt.dll
- DbCrypt.conf
- KeyHolder.dll
- KeyHolder.conf - this is the text file with keys, it is only for the developer's usage, it should not be sent to end-users!
3. Put the following files into Firebird root from the folder \Windows_64bit\WindowsServerPart_64bit
- fbcrypt.dll
- libcrypto-1_1-x64.dll
- libssl-1_1-x64.dll
- gbak.exe
- firebird.msg
- firebird.conf (optional, can be used as an example)
4. Connect to the unencrypted database with isql and encrypt the database:
isql localhost:C:\Temp\EMPLOYEE30\EMPLOYEE30.FDB -user SYSDBA -pass masterkey
SQL>alter database encrypt with dbcrypt key red;
SQL> show database;
Database: localhost:C:\Temp\EMPLOYEE30\EMPLOYEE30.FDB
Owner: ADMINISTRATOR
PAGE_SIZE 8192
Number of DB pages allocated = 326
Number of DB pages used = 301
Number of DB pages free = 25
Sweep interval = 20000
Forced Writes are OFF
Transaction - oldest = 2881
Transaction - oldest active = 2905
Transaction - oldest snapshot = 2905
Transaction - Next = 2909
ODS = 12.0
Database encrypted
Default Character set: NONE
Please note - you can always check that database is encrypted with show database; command in isql, or use gstat -h databasename.
Let's consider the details of the encryption command:
alter database encrypt with dbcrypt key red;
alter database encrypt with "DbCrypt" key Red;
After that, the database is encrypted with server-side authentication: the keys are located in the file KeyHolder.conf.
In the table below you can see files we have on the server to enable the encryption, and what we need on the client-side:
| On the server's side (Firebird-3.0.3.32900-0_x64) | On the client's side (demo - CryptTest.exe) - 32bit |
|---|---|
| Mandatory files: | Mandatory files: |
| plugins/dbcrypt.dll | fbclient.dll |
| plugins/keyholder.dll | fbcrypt.dll |
| DbCrypt.conf | libcrypto -1_1.dll |
| libssl-1_1-x64.dll | Optional files: |
| libcrypto-1_1-x64.dll | firebird.conf |
| fbcrypt.dll | |
| Files for gbak with encryption: | |
| gbak.exe | |
| firebird.msg | |
| Optional files: | |
| plugins/KeyHolder.conf (for initial encryption in development mode) | |
| firebird.conf (contains parameter to set encryption plugin) |
Step 2: Connect to the encrypted database with the client application
If you want to connect to an encrypted database with your developer tools first - please read Step 3 below.After the initial encryption, we suppose that the database will be copied to the customer environment, where access to it will be done only through the authorized application.
To imitate such an environment, we need to remove (or simply rename) the file with keys (KeyHolder.conf) from the folder plugins.
Without KeyHolder.conf, the encryption plugin will require receiving the key from the connected application. The example of such an application is included in the CryptTest.zip archive with the demo plugin – there is a compiled version and full sources for it on Delphi XE8. There are also examples for Lazarus, .NET, and PHP.
The code to initialize an encrypted connection is very simple – before the usual connection, several calls should be done to send an appropriate key. After that, the client application works with Firebird as usual.
Run the demo application to test the work with the encrypted database, it is in the folder \Example_Delphi_EnhancedCryptTestClient\Win32\Debug.
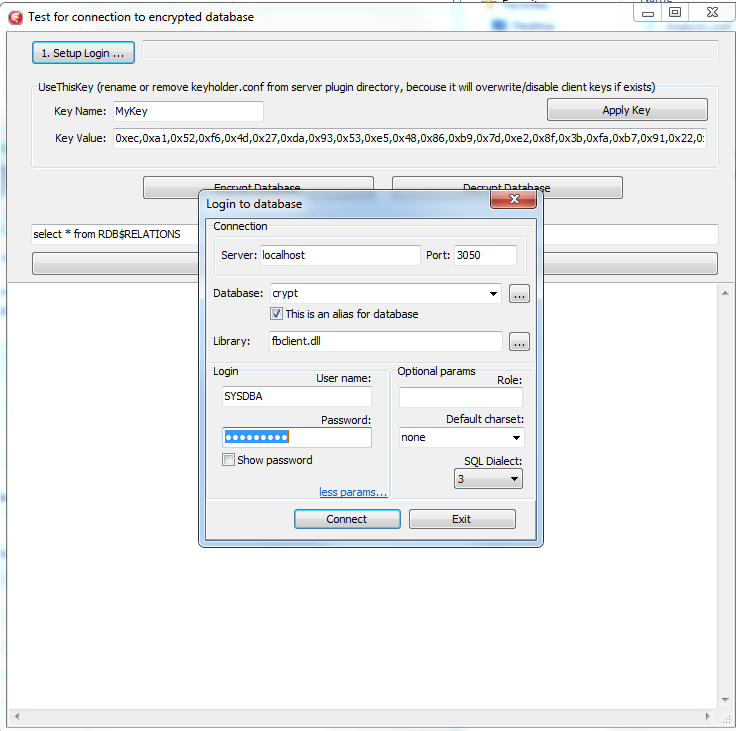
Do the following steps:
- Specify database path or alias in "1. Setup Login". This database will be used in the next steps.
- Specify the key name and value to be used. If you have previously used key RED, fill into the edit box "Key Name" value RED and copy the key value from the KeyHolder.conf file.
- You can encrypt and decrypt the database with the specified key. Please note - encryption takes time, and it requires to have an active connection to the database
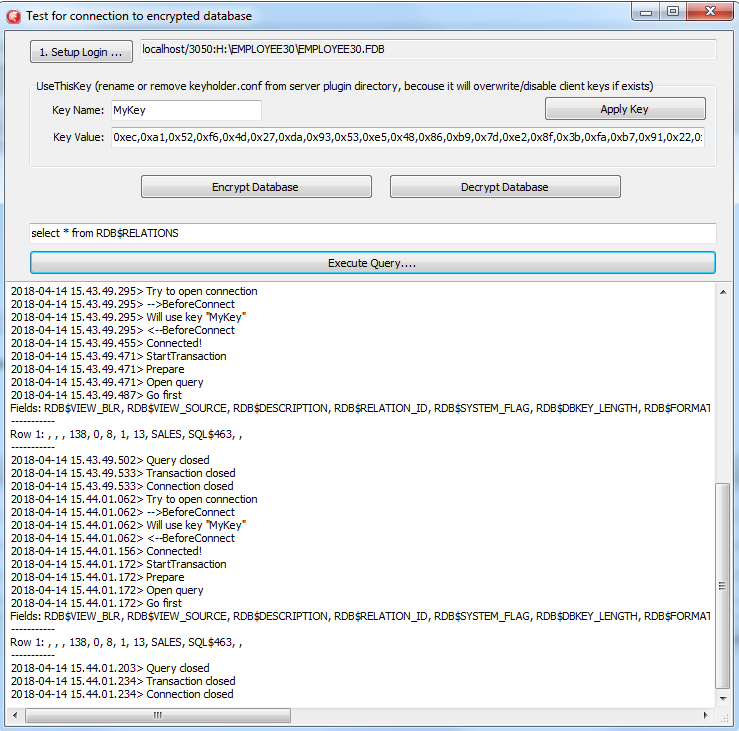
- Click Execute query to test the connection to the encrypted database with the simple select
Please note: the test application can connect to the encrypted database only through TCP/IP, xnet is not supported.
In the example of the client application, all database operations (connection, transaction start, transaction's commit, query start, etc) are made in a very straightforward way to demonstrate all steps of the operation against the encrypted database. You can use this code as an example for the implementation of encryption in your applications.
Step 3: Connect to the encrypted database with developer tools
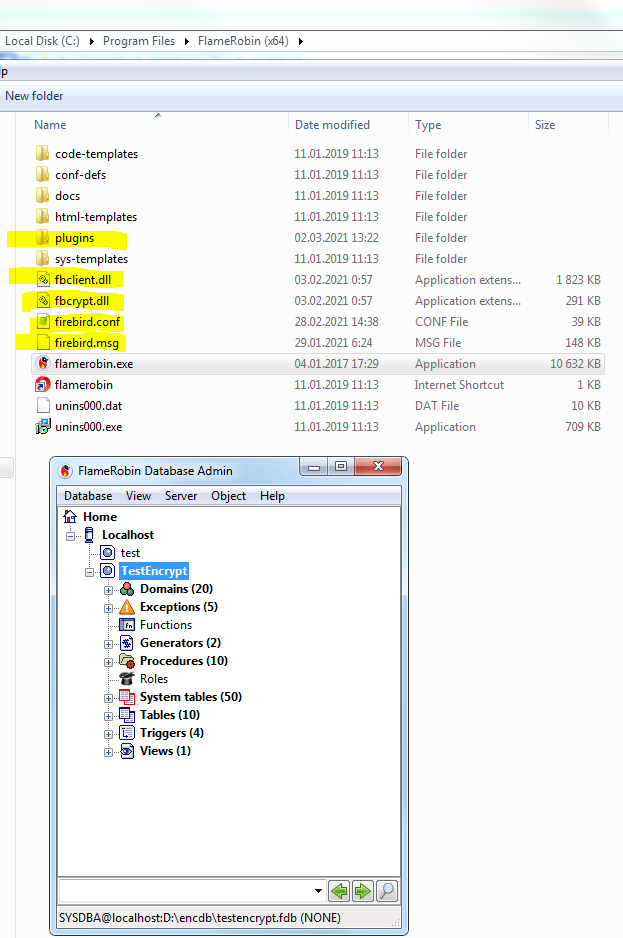
Starting with v2021 of Encryption Plugin Framework for Firebird, it is possible to load keys in the client library (fbclient.dll), without modification of the client software.It enables the transparent work of Firebird developers tools (like SQLLY Studio, DatabaseWorkbench, IBExpert, FlameRobin, RedExpert, etc), and transparent usage of Firebird command-line tools (gfix.exe, nbackup.exe, etc).
To set up such a connection for a client application, you need to know its bitness (32bit or 64bit):
- The Firebird command-line tools like isql.exe, gfix.exe, nbackup.exe have the same bitness as a server, so you need to copy files from the folder Windows_64bit\WindowsClientPart_64bit to the same folder where the client application resides
- For developer tools which are usually 32bit, you need to copy 32bit client files from folder \Windows_32bit\WindowsClientPart_32bit to the same folder where the client application resides.
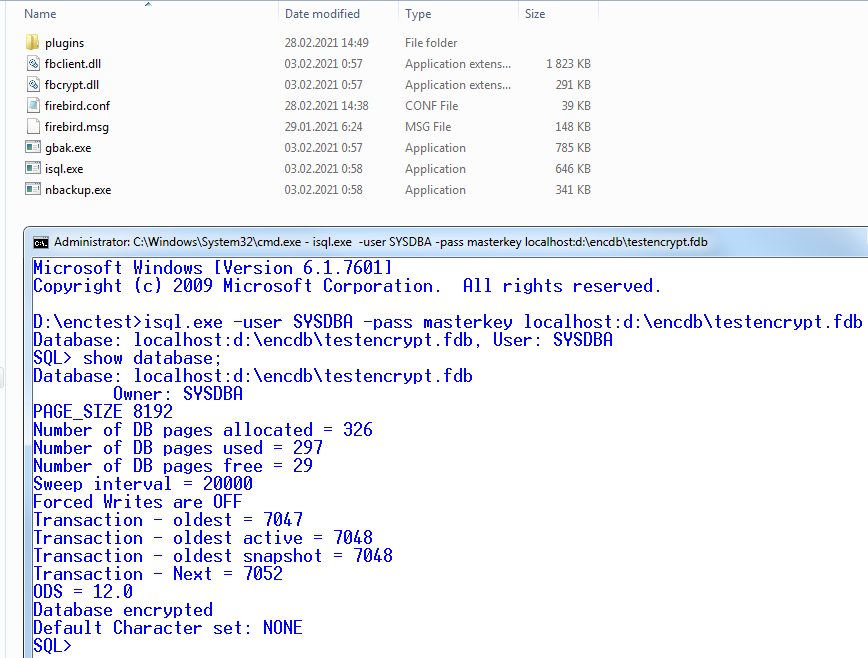
Let's consider in details what happens here:
- The client application (isql.exe in our case) starts and load Firebird client library fbclient.dll
- fbclient.dll read configuration file firebird.conf and sees the parameter KeyHolderPlugin=KeyHolder, which instructs to load plugin keyholder.dll from the standard subfolder plugins.
- fbclient.dll loads keyholder.dll, and then keyholder.dll reads key storage file KeyHolder.conf, and sees there key Red, which was used to encrypt our test database
- isql successfully connects to the encrypted database and shows its status
Important Note 1: gbak.exe, if it will be used with client-side key load, will create an unencrypted backup file! To prevent it, we recommend using gbak.exe from FEPF with explicit key parameters, because it creates encrypted backup files!
Important Note 2: nbackup.exe will create encrypted incremental copies.
Step 4: Backup and restore of the encrypted database
The full verified backup with gbak.exe is the primary backup method for Firebird databases. The standard Firebird distribution includes command-line tool gbak.exe to perform it, however, it will not work with the encrypted database in the production mode (without keys on the server or without a key loading on the client-side, as we described earlier). After the encryption, only authorized applications can access an encrypted database, and standard gbak is not an authorized application.We all know how important backup and restore for the database health and performance, so, in order to perform backup and restore for the encrypted databases, we have developed gbak.exe with the encryption support, and included it into the FEPF.
It is important to say, that this gbak.exe produces the encrypted backup file: it encrypts the backup with the same key as for the database encryption.
If you run gbak.exe from the plugin files with the switch -?, you will see the new parameters of gbak.exe, which are used to work with the encrypted databases:
-KEYFILE name of a file with DB and backup crypt key(s)
-KEYNAME name of a key to be used for encryption
-KEY key value in "0x5A," notation
Let's consider how to use gbak.exe with encrypted databases and backups.
Backup encrypted Firebird database
To backup an encrypted Firebird database, gbak.exe must provide the key for the server. This key will be used to connect and read the database and to encrypt the backup file.There are 2 ways to supply the key for gbak.exe: store key in the key file or explicitly put it in the command line:
Example of backup with the encryption key in the key file:
gbak.exe -b -KEYFILE h:\Firebird\Firebird-3.0.3.32900-0_Win32\examplekeyfile.txt -KEYNAME RED localhost:h:\employee_30.fdb h:\testenc4.fbk -user SYSDBA -pass masterkeyHere, in the parameter -KEYFILE we specify the location of the files with keys, and in -KEYNAME - the name of the key being used. Please note, that the file examplekeyfile.txt has the same structure as KeyHolder.conf.
Example of backup with the explicit key:
gbak -b -KEY 0xec,0xa1,0x52,0xf6,0x4d,0x27,0xda,0x93,0x53,0xe5,0x48,0x86,0xb9,0x7d,0xe2,0x8f,0x3b,0xfa,0xb7,0x91,0x22,0x5b,0x59,0x15,0x82,0x35,0xf5,0x30,0x1f,0x04,0xdc,0x75, -keyname RED localhost:h:\employee30\employee30.fdb h:\testenc303.fbk -user SYSDBA -pass masterkeyHere, we specify the key value in the parameter -KEY, and the name of the key in the parameter -KEYNAME. It is necessary to specify key name even if we supply the explicit key value.
Restore the backup to the encrypted Firebird database
The gbak can also restore from the backup files to the encrypted databases. The approach is the same: we need to provide the key name and key value to restore the backup file.See below examples of the restore commands:
Example of restore with the encryption key in the keyfile:
gbak -c -v -keyfile h:\Firebird\Firebird-3.0.3.32900-0_Win32\examplekeyfile.txt -keyname white h:\testenc4.fbk localhost:h:\employeeenc4.fdb -user SYSDBA -pass masterkey
Example of restore with the explicit key:
gbak -c -v -key 0xec,0xa1,0x52,0xf6,0x4d,0x27,0xda,0x93,0x53,0xe5,0x48,0x86,0xb9,0x7d,0xe2,0x8f,0x3b,0xfa,0xb7,0x91,0x22,0x5b,0x59,0x15,0x82,0x35,0xf5,0x30,0x1f,0x04,0xdc,0x75, -keyname RED h:\testenc4.fbk localhost:h:\employeeenc4.fdb -user SYSDBA -pass masterkey
If you restore from an unencrypted backup file with encryption keys (gbak -c -keyfile ... -keyname ...) , the restored database will be encrypted.